Billing
Last updated: Jul 10, 2026
The billing model is based on the authors' monthly activity, specifically focusing on changes made to the source code within the platform's registered repositories.
The billing begins on the first business day of each month, with the generation of the previous month's author list. This list is manually reviewed to eliminate any duplicate authors, as an author might have used other accounts to make some commits in addition to those made using their primary email/account. Fluid Attacks then employs this refined list to calculate the organization's billing for the month.
- All authors who change the source code of a repository registered on the platform will be charged (for either additions, modifications, or deletions).
- Those who change only files in excluded paths are identified and not billed.
- Bots will count as authors, and they will be charged if they contribute to files within scope. The reasons for the latter are that the code they generate there may introduce vulnerabilities, will be tested and will be covered by the accuracy SLA. If you want to make sure their contributions are not charged, have them contribute only to excluded paths.
It is crucial to clarify that billing is conducted based on the date commits are merged into the configured branch within the platform, not their creation date. This approach ensures that code analysis begins from that particular moment forward.
Due to this, it's possible for the billing to include authors who didn't commit during the month being billed. This situation may arise when changes are made in branches prior to the final version (pre-release), and subsequently, these commits are integrated into the active branch registered in the platform. It's important to note that the date we observe a commit may not coincide with its original authorship date.
When a repository is registered on more than one branch
(multi-branch support),
each registered branch is billed independently
for the month in which its commits are observed as merged.
Because of this,
an author who makes changes that reach different branches
in different months can be billed twice.
Modifying the Git history may result in additional charges.
Author identification
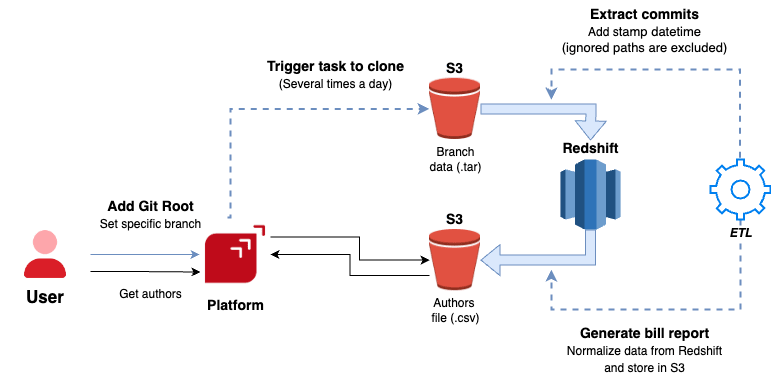
Through this process, we obtain all the authors (individuals or bots) whose changes (additions, modifications, deletions) to the source code we observe as merged on a date within the previous month. To accomplish this, we rely on the Git history information of each repository, focusing solely on the branch configured within the platform. The diagram below illustrates the procedure necessary for generating the authors' report. The next subsections explain the details of author identification in simple terms.
Preliminary considerations
Author identification relies on the following:
- Git, a distributed version control system,
providing the "change history" for code projects.
It allows to
- save versions of a developer's work through "commits";
- track every change made, who made it, and when;
- create branches to work on new features in isolation, then merge them into the main project.
- Synchronization of the commit history from a Git repository with Fluid Attacks' Snowflake database.
- Snowflake, providing Fluid Attacks a sole database where the complete and permanent history of all commits is stored. It is the single source of truth for all analysis.
- DynamoDB, a component to store the hash of the last processed commit. This tells Fluid Attacks where to resume in the next run, which avoids slow and costly queries to Snowflake.
- The unique commit identifier,
to check if a commit already exists in Snowflake.
The system uses a combination of
group name,repository nicknameandcommit hash.
Process
The process is divided into the following steps:
- Cloning: The system clones the latest version of the Git repository to ensure it has the most recent history.
- Checking of the starting point:
It is required to know the point
from which new commits are registered:
(a) The system queries DynamoDB to get the hash of the "commit of reference" (the last commit saved in Snowflake).
(b) The system searches for the hash in the newly cloned repository's history to confirm that the history has not been altered. - Scenario 1: The commit of reference exists:
In this most common and efficient scenario
(a) The system finds the commit of reference in the history.
(b) The system iterates through the Git history starting from the commit of reference and inserts only the new commits into Snowflake.
(b) DynamoDB stores the hash of each newly inserted commit, updating the commit of reference. - Scenario 2: The commit of reference does not exist:
This scenario is triggered if the Git history was rewritten,
making the DynamoDB "marker" invalid.
In this scenario
(a) The process does not find the commit of reference, which indicates that the history integrity has changed.
(b) To ensure no information is lost or duplicated, the system initiates a full synchronization:
(i) It iterates through the entire Git history, from the first commit to the last. For each commit, it checks Snowflake (usinggroup name,repository nicknameandcommit hash) to see if it has already been recorded.
(ii) If a commit is not in Snowflake, the system inserts it. This method is slower than that in Scenario 1, but it is a measure that guarantees data consistency even when Git history is modified. - Author count: When billing a client, Fluid Attacks validates all the commits inserted into its database (Snowflake) during the corresponding month. The authors of these commits are counted (each author is counted only once), and the total determines the amount to be charged to the client.
Billing report generation
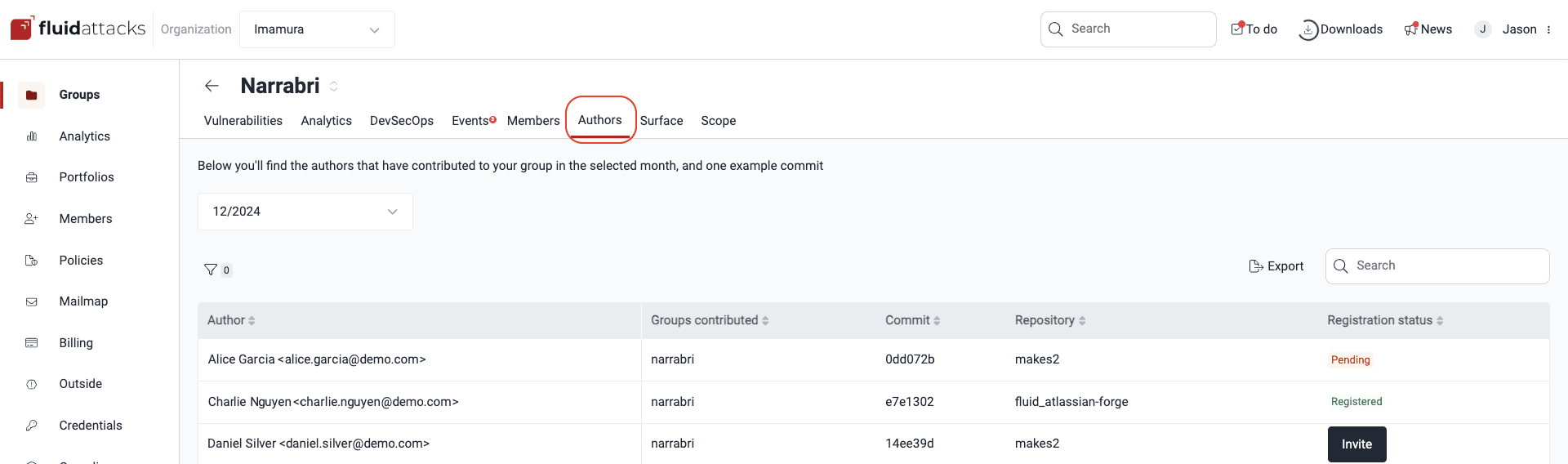
In this phase, the process involves eliminating duplicate commits and consolidating information gathered from all organization repositories. These lists include author names, the groups they have contributed to, commit IDs, and repository names, each providing an example for every author. Authors who contribute only to files outside the testing scope are excluded.
In the process, a commit's uniqueness is determined by the absence of duplications in the information. This validation encompasses fields like the author's name, email, date of authorship, and message content. Any alteration in these aspects renders the commit eligible for billing inclusion.
Lastly, these reports are accessible for review on the platform, both in your organization's Billing section and your groups' Authors section.
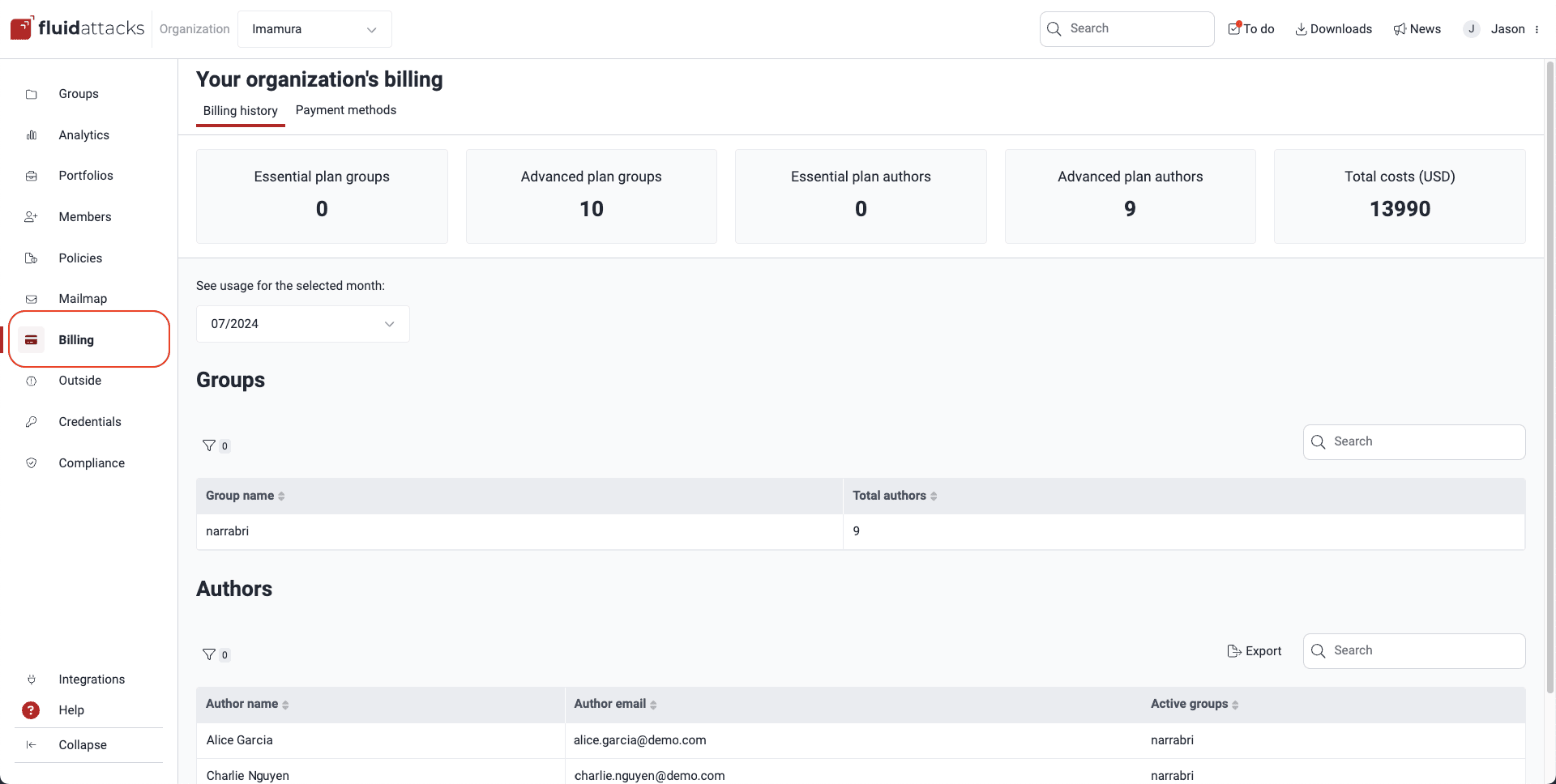
Use the filters to explore authors easily.