Regenerative infrastructure
Last updated: Jun 30, 2026
We deploy our infrastructure every day in line with these key concepts:
This approach has many benefits in terms of business continuity and disaster recovery. By adopting infrastructure as a code, and based on AWS, Terraform, and GitLab CI features, we can:
-
Destroy and deploy infrastructure quickly. We redeploy the infrastructure constantly because autoscaling is done daily, based on usage. In such an infrastructure environment, it is expected that a server could not exist for more than 24 hours. This is the reason why we regenerate our infrastructure on a daily basis with an automated process while autoscaling.
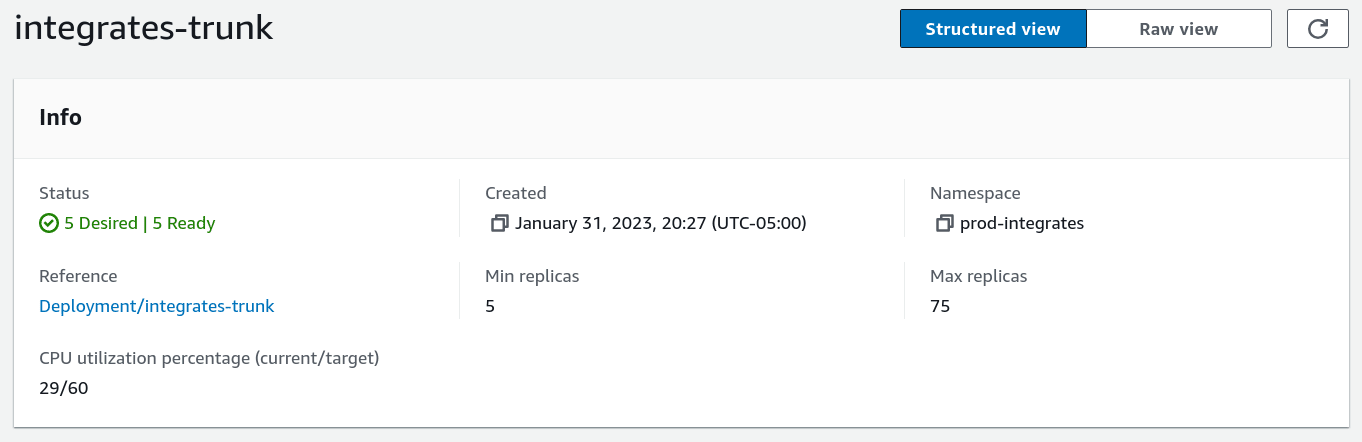 Pod-level autoscaling for the production deployment of the platform
Pod-level autoscaling for the production deployment of the platform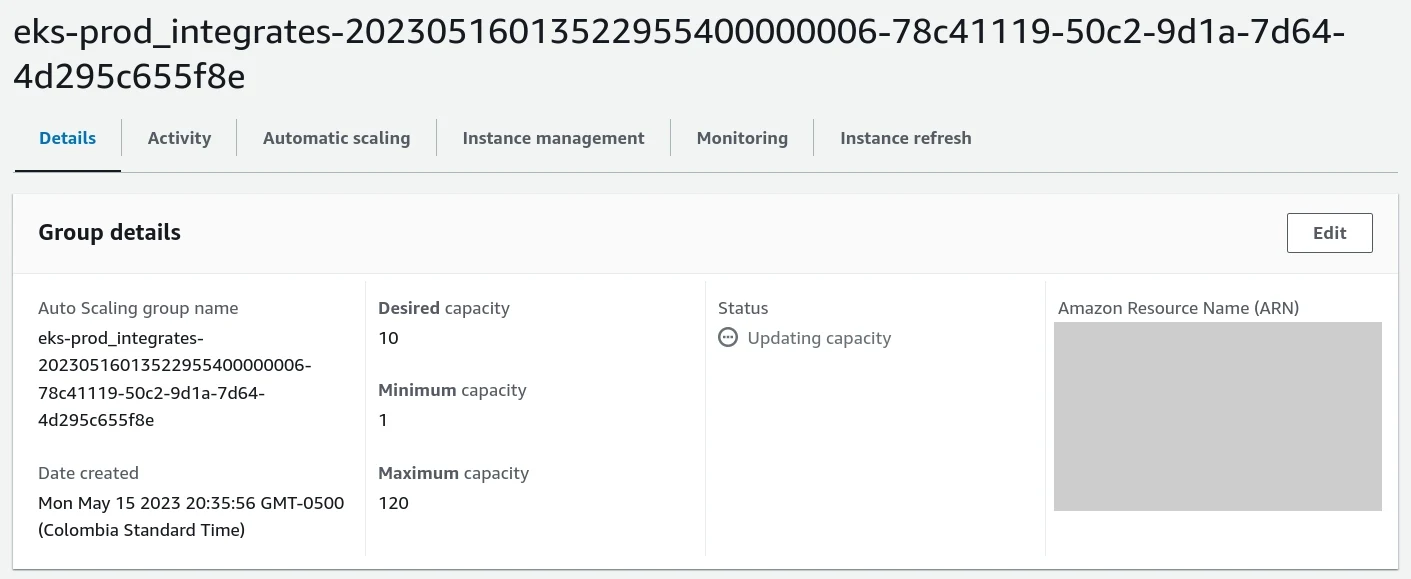 Node-level autoscaling for the platform
Node-level autoscaling for the platform -
Monitor and review all the code in search of bugs or any other type of errors.
-
Continuously hack our own code, infrastructure included.
Additionally, we have an extensive backup strategy and well-defined recovery objectives.
Other resilience measures
Everything is decentralized
Fluid Attacks uses decentralized, multi-region data centers (without requiring local networks) and SSO-authenticated Wi-Fi with WPA2-AES encryption.
Role coverage
Fluid Attacks ensures operational continuity by maintaining at least two people per role, preventing service gaps during talent absences or emergencies.