Sorts
Sorts is the product responsible for helping End Users sort files in a Git repository by its probability of containing security vulnerabilities. It does so by using Machine Learning and producing a Model that is then used by:
- End users as a Free and Open Source CLI tool.
- Fluid Attacks internal systems, to update the priority in Integrates of the source code that Fluid Attacks Hackers audit.
Public Oath
Sorts CLI can be executed using Makes. Refer to Getting Started for more information.
Architecture

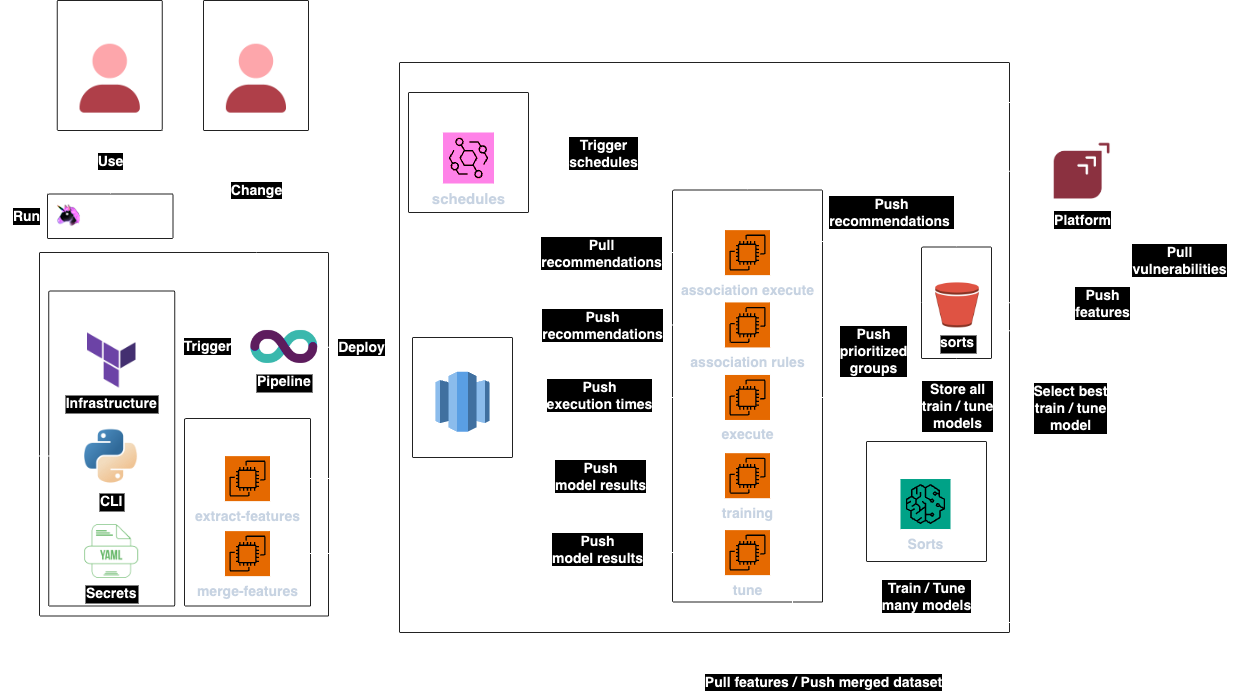
- Sorts is a CLI application written in Python.
- It can be used by anyone via Makes.
- It declares its own infrastructure using Terraform.
- Sensitive secrets like Cloudflare authentication tokens are stored in encrypted YAML files using Mozilla SOPS.
- It uses a Machine Learning Pipeline architecture, where many models are trained and improved automatically as the data evolves, and the best model is chosen according to some predefined criteria set up by the Sorts Maintainer.
- It reports statistics to the Redshift cluster provided by Observes, which allows us to monitor the progress of the model over time, and intervene in the pipeline if something doesn't go as planned.
- The source data is taken from the git characteristics of files at Integrates which are reviewed by human hackers to determine if they are vulnerable, then the filenames are used to extract git characteristics using their repository's commit history and create the dataset that will be used to train Sorts model.
- The pipeline consists of the following steps:
extract-features: Triggered and executed by GitLab CI. Clone all source code repositories, and produce a dataset with the features for each file in the repository.merge-features: Triggered and executed by GitLab CI. Take the features from the previous step, and merge them into a dataset.training: Triggered by AWS EventBridge and executed by AWS Batch. Take data frommerge-features, train different models using SageMaker, and upload the best one to S3.tune: Triggered by AWS EventBridge and executed by AWS Batch. Take the best model fromtraining, tune it using different parameters, and upload the best one to S3.execute: Triggered by AWS EventBridge and executed by AWS Batch. Take the "Best Model" and use it to prioritize the files at Integrates.association*: Triggered by AWS EventBridge and executed by AWS Batch. Recommend the type of vulnerability that files may contain.
Contributing
Please read the contributing page first.
Development Environment
Follow the steps in the Development Environment section of our documentation.
If prompted for an AWS role, choose dev,
and when prompted for a Development Environment, pick sorts.